

Based on the study entitled Splits or waves? Trees or webs? How divergence measures and network analysis can unravel language histories
Same Languages, Different Visions
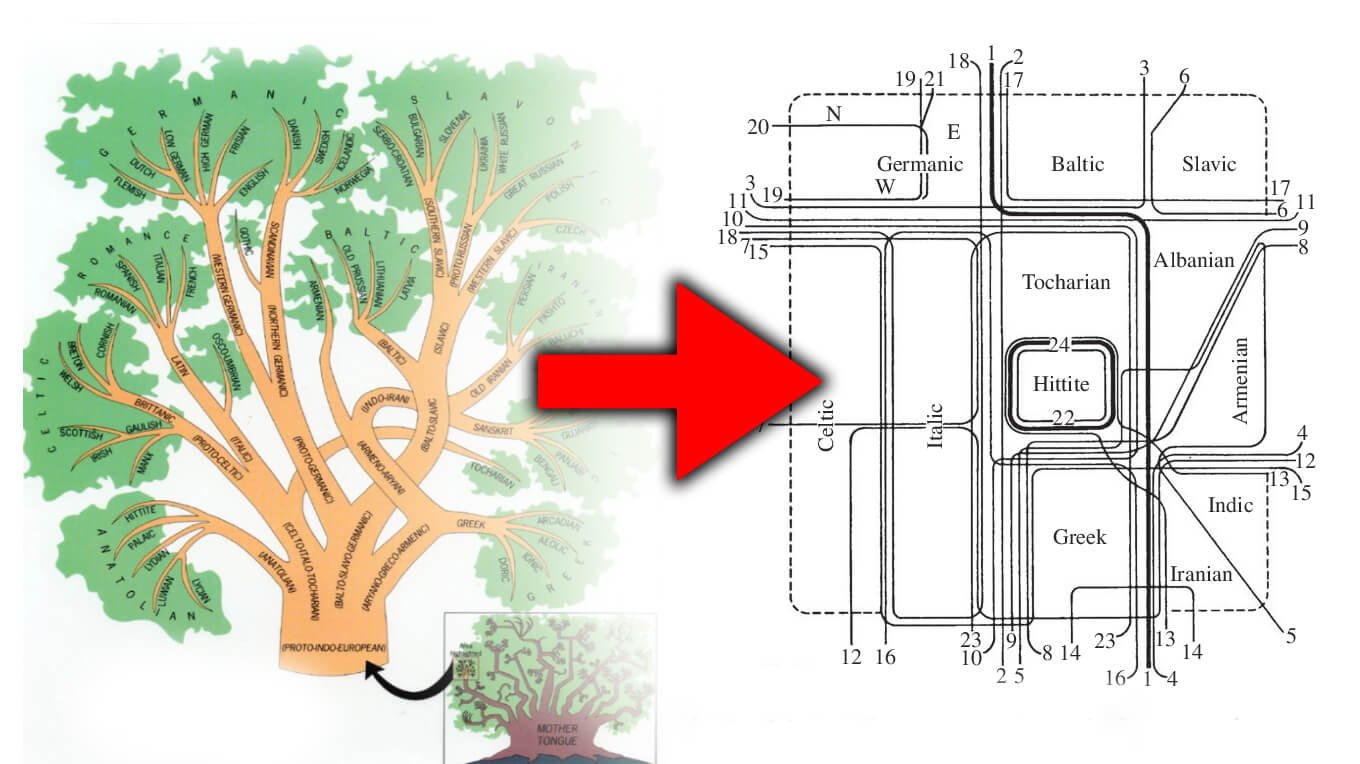
In exploring the divergence of languages within a family, linguists traditionally use models such as 'splits' and 'waves.' The 'splits' model is akin to a branching tree, where languages diverge distinctly from a common ancestor, while the 'wave' model represents a more interconnected dialect continuum. This study illustrates the difference between these models using the Indo-European language family. Figures 1 and 2 depict trees with clear binary splits, while Figures 3 and 4 present a NeighborNet analysis showing a web of cross-cutting relationships. These contrasting representations highlight the complexity of language divergence and reflect different historical processes.




The tree models suggest distinct separations between speaker populations, often through migrations. Conversely, the wave model indicates expansions over continuous territories where dialects overlap and influence each other. The study emphasizes that real-world language histories often involve both processes, requiring models that can integrate tree-like and web-like signals. Phylogenetic network methods, such as those discussed in this paper, offer a means to capture this complexity. They combine elements of both models, providing a more accurate reflection of the historical divergence of languages.
Language Divergence and the Real World: Two Models, One Reality
The splits and wave models reflect two different real-world processes. The split model corresponds to populations dividing and migrating away from each other, leading to distinct language branches. The wave model represents populations expanding over contiguous territories, maintaining local contact and resulting in overlapping dialects. Understanding these processes is crucial for interpreting the historical relationships between languages within a family. Real-world factors such as demographic movements, socio-political changes, and cultural interactions are the primary drivers of language divergence.
The study stresses that language divergence patterns are direct reflections of these historical processes. Linguistic changes occur naturally, but the extent to which these changes spread or remain isolated depends on the real-world context. For example, vast expansions, such as those driven by the Roman Empire, created the Romance language family, while isolated groups like the Albanians and Armenians developed independently. Borrowing and contact between languages further complicate the divergence patterns, as seen in scenarios where initial splits are followed by later interactions. This complexity necessitates models that can distinguish between splits and waves and accurately represent the intertwined nature of language histories.
Network Methods: Best of Both Worlds?
Network methods, particularly the Network algorithm and NeighborNet, are effective in capturing both split-like and wave-like signals within language divergence data. Developed initially for biological sciences, these methods have been adapted for linguistic studies. Network takes individual state data, focusing on specific linguistic changes, while NeighborNet uses overall measures of distance between languages. Both methods can represent the mixed nature of language divergence, combining elements of tree-like branching and web-like continua.

Figure 5.
Unrooted network of 19 Germanic language samples. (Reproduced with permission from Forster et al. 2006, p. 134.)
The Network algorithm, for example, has been applied to limited datasets of Celtic and Germanic languages, demonstrating its potential to represent complex relationships. NeighborNet, on the other hand, has been used with various linguistic datasets, including phonetic divergence measures for Germanic languages. These network methods reveal patterns that align well with known historical contexts, such as the clear splits between English and continental Germanic varieties and the web-like patterns within regional dialects. Despite some limitations, such as the placement of intermediate dialects, network methods provide a nuanced view of language divergence that tree-only models cannot achieve.


Measuring Network Versus Tree Signals
Both Network and NeighborNet can effectively visualize the strengths of tree-like and web-like signals within language divergence data. Network identifies individual linguistic changes within the network diagram, providing a detailed view of specific innovations and retentions. NeighborNet, while using distance measures, captures the overall balance between branching and continuum patterns, reflecting the mixed nature of real-world language histories. These methods allow researchers to assess the degree of tree-ness or net-ness in a dataset, providing insights into the historical processes that shaped language divergence.
For example, NeighborNet analyses of Germanic languages show clear splits corresponding to historical separations, such as the isolation of English varieties, while also depicting the continuum of dialects across continental West Germanic. These patterns align with known historical expansions and migrations, demonstrating the utility of network methods in capturing the complexity of language divergence. By integrating tree-like and web-like signals, network methods offer a more comprehensive representation of language histories, accommodating the multifaceted nature of linguistic evolution.
State Versus Distance Data: Theory and Practice
The study compares state data, which focus on specific linguistic changes, and distance data, which measure overall divergence between languages. Network methods like the Network algorithm use state data to identify individual changes, while NeighborNet employs distance measures to represent the overall divergence pattern. Both approaches have their strengths and limitations. State data provide detailed insights into specific innovations, but distance measures can capture the broader divergence pattern, reflecting the combined impact of all linguistic changes.
NeighborNet analyses of Germanic languages, for example, reveal patterns that correspond well to known historical contexts, such as the separation of English varieties and the continuum within continental West Germanic. These results demonstrate that distance measures can effectively represent language divergence, even without specifying ancestral states. The study proposes that the randomness of parallel innovations and shared retentions ensures that their effects balance out, leaving the non-random patterns of shared innovations to dominate the overall divergence pattern. This principle explains why distance measures can reflect language histories accurately, supporting the use of network methods in linguistic research.
Lessons for Historical Linguistic Methodology
The study emphasizes the need for balanced approaches that integrate both state and distance data, as well as tree-only and network methods, to uncover the full complexity of language histories. While tree models are useful for specific purposes, such as dating language divergence, network methods provide a more comprehensive representation of the mixed nature of linguistic evolution. By capturing both split-like and wave-like signals, network methods offer valuable insights into the historical processes that shaped language divergence.
The application of these methods to Germanic languages demonstrates their effectiveness in reflecting known historical contexts, suggesting their utility for probing the early divergence history of other language families, such as Indo-European. The study highlights the importance of considering real-world factors, such as demographic movements and socio-political changes, in interpreting language divergence patterns. By integrating these factors, network methods can provide a more accurate and nuanced view of language histories, enhancing our understanding of linguistic evolution and prehistory.





